
python入门
python作为一门面向对象编程的语言,有着许多优点,我们可能已经听到过很多关于python的传说,比如这些年大火的人工智能领域涉及的机器学习,图像识别,自动化办公领域涉及的文件批量化处理,自动分析,导出报表等。
事实上,python之所以被如此广泛的应用,得益于它的语法简单,阅读容易,而且开源,与C/C++、JAVA、C#等老牌编程语言相比,仅需几行代码就能实现其他编程语言花几十行才能实现的效果。跨平台的特点也使得它备受各种第三方库的青睐[1]小白师哥.知乎——python为什么更适用于AI[OL],2021-11-03参考资料。
使用python完成一些办公过程中的重复操作,能够很好的起到事半功倍的效果。
首先,针对python零基础入门,我推荐是通过视频网课或者在线网站教程进行学习,同时辅以相应的工具书,便于编写过程中自行查阅。
以下是我学习过程中用到的自觉比较浅显易懂的学习网站和工具书。
- 在线学习网站:
- 这个网站的优点在于有个讨论的社区环境,遇到不懂的地方可以直接评论提问,而且还有打卡和线上编写简单程序的功能,学习的反馈周期比较短,不容易感到枯燥。如果单纯是以本帖讨论的自动化办公极限编程而言,学完到《模块》为止的前七章就足够了。重点是要了解python中用到的数据结构和条件、分支、循环等语句的运用,当然还包括python原生的几个自带的函数方法。在接下来的自动化办公中,会经常需要用到循环迭代和字典数据结构相关的内容。
- 工具书,此处提供电子版:
- 这本工具书的优点就是它的内容是完全面向纯新手的,从python安装到使用,每一步都详细说明。同时提供教学示例和开发实例。不过实际教学内容和上文的在线网站其实是类似的。有实体工具书的话,主要是方便学习记忆。毕竟拿在手里的学起来比较有实感。


引文
因为我们的目的是使用python来完成办公过程中重复次数较多的工作,所以我这里就以标书编制过程中,比较繁琐的人员安排表编写和人员简历表导出两个情景作为编写实例进行讲述。
我会从程序编写完成后期望实现的交互情景入手,提取出交互过程中的输入输出内容,并根据输入输出过程中遇到的问题提供查找答案的思路,最后提供编写完成的带详细注释的实例源码。
这两个实例的原理了解以后,有兴趣学习的小伙伴可以以此为框架,完成对任何一种excel格式存储的数据源进行横向纵向数据切片的任务,同时根据导出的数据源渲染任意重复用到该导出数据源的表格模板。从复用性和实用性上来说,这两个实例还是很有参考价值的。
实例1——数据切片导出
- 首先,我们的目的是要把需要的人员信息从堪称琳琅满目的人员清册中提取出来,所以至少第一步,我们要把人员清册导入。导入的人员清册作为一个变量,方便后面使用python对其进行操作。
- 然后,按照以往编制的经验来看,我们挑选人员是以评分表中的资质证书要求为参考方向,然后根据评分要求决定大概需要多少人,所以第二步应当考虑根据具体的搜索条件匹配和需要的人数来进行对人员清册表中行的提取。
- 在对行进行提取,也就是完成了横向截取切片此处用截取,是因为需要把根据输入的搜索条件匹配到的人员信息取出并存放到新的变量中,用截取强调此操作涉及数据源和新的数据容器两个变量以后,需要根据简历表格式或者招标文件给出的人员安排表表头,对冗余的列进行裁剪,完成纵向裁剪切片此处用裁剪,是因为这一步操作是对截取出的新的数据列表进行裁切,去掉多余列,用裁剪强调此操作是仅对新的数据容器这一个变量进行操作。
- 最后,因为之前只是对缓存中的数据进行操作,我们还需要将完成横向纵向切片的数据导出到新的excel文件里进行保存。
- 由此确定了最初的输入输出框架:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30"""
输入示例:
OUT:请输入文件路径:
IN:售前投标用人员清册.xlsx
OUT:正在对数据进行清洗,去除空值,补全缺值。
OUT:请输入需要查询的列值信息及所需数量,如"证书1,测绘作业证,3"
IN:证书1,测绘作业证,3
OUT:查询到n条信息,是否继续添加,YES OR NO
IN: YES
OUT:请输入需要查询的列值信息及所需数量,如"证书1,测绘作业证,3"
IN:证书1,测绘作业证,3
OUT:查询到n条信息,是否继续添加,YES OR NO
IN: NO
OUT:已获取您所需的表格信息,请输入您所需表头对应的列名。
OUT:请输入您所需的表头:
IN:姓名,性别,年龄,证书资质,学历
OUT:信息整合完毕,请输入您想要保存的文件名:
IN:投标人员信息表.xlsx
OUT:已完成导出
"""编写过程梳理
根据设计好的输入输出示例,我画出了相应的流程图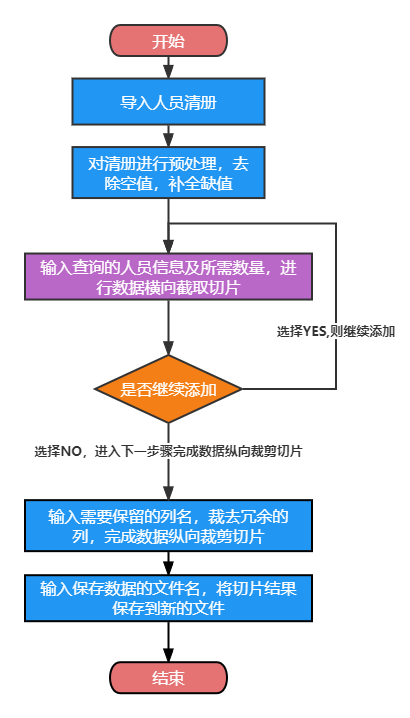
然后在流程图基础上罗列出基本的代码框架
1 | #===============================导入人员清册==================== |
根据代码框架,罗列TODO,并根据自己对python中列表、字典等数据结构的了解和条件、分支、循环等语句的运用,提取相应的搜索关键词,确定搜索方向。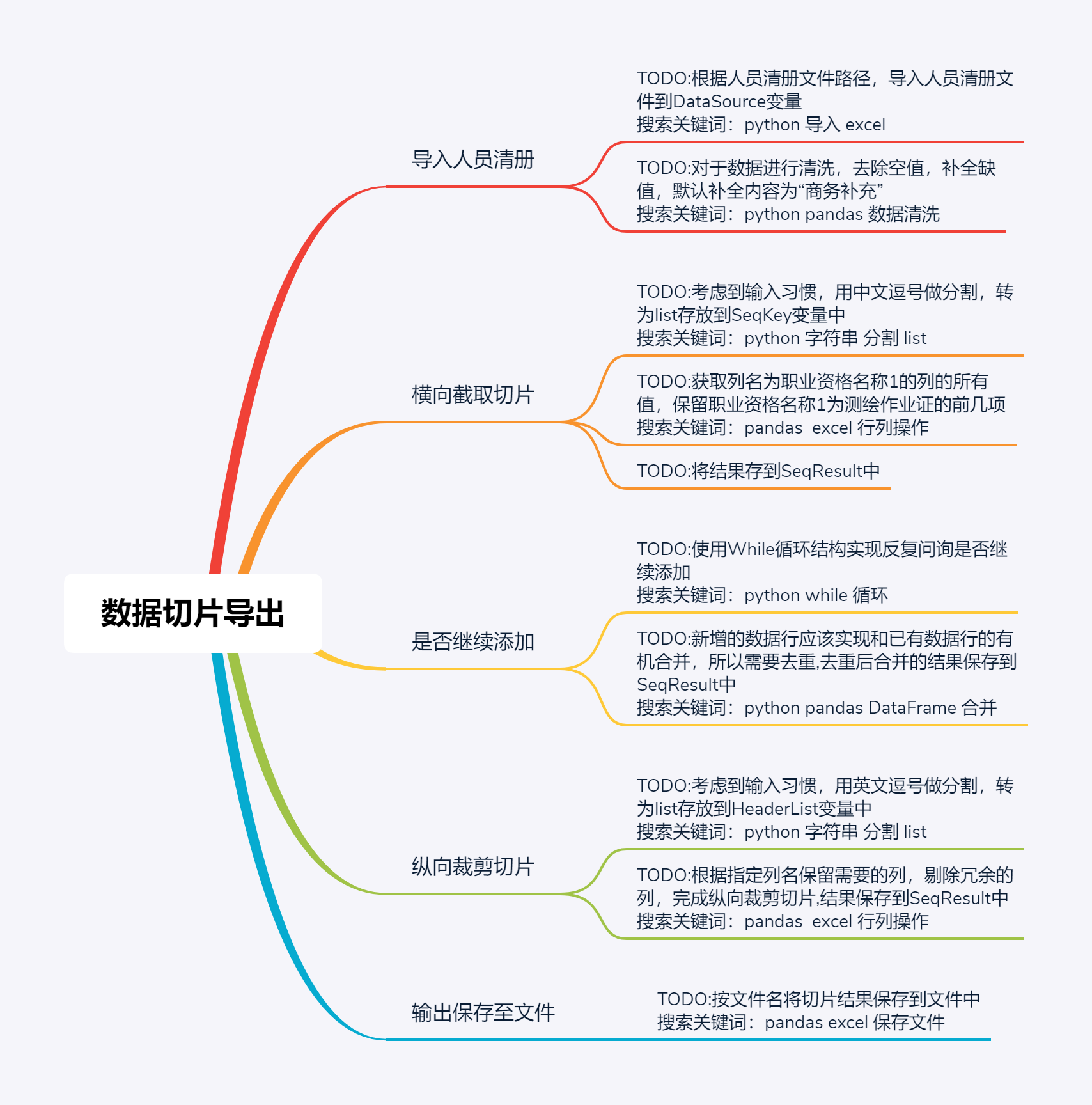
因为要考虑到使用者的具体感受,所以推荐在解决了TODO以后,再通过print()函数写一些提示性文字,提示输入示例,引导输入。
1 | import os |
| 变量名 | 数据类型 | 变量释义 |
|---|---|---|
| DataSourceInput | 字符串string | 输入的数据源文件名 |
| DataSource | 二维数据表结构DataFrame | 根据文件名获取数据源后存放于此变量 |
| SeqInput | 字符串string | 数据横向截取所需的列值信息及所需数量 |
| SeqKey | 列表list | 将SeqInput按“,”分割后获得的列表,便于操作 |
| SeqCache | 二维数据表结构DataFrame | 按照输入的列值信息截取出的数据行 |
| SeqResult | 二维数据表结构DataFrame | 存放截取的数据行的数据容器 |
| BreakInput | 字符串String | 输入判断是否继续添加,YES OR NO |
| BreakKey | 字符串String | 对BreakInput进行大小写规范化 |
| HeaderListInput | 字符串String | 数据纵向裁剪所需的表头信息对应列名 |
| HeaderList | 列表list | 将HeaderListInput按“,”分割后获得的列表,便于操作 |
| SaveFile | 字符串String | 存放切片结果的文件的名字 |
1 | import os #os库,涉及文件操作需要用到这个库 |
实例2——简历表自动生成
- 第一步,要把实例1导出的人员信息进行导入,这部分的代码可以参考实例1,复用导入的代码。
- 第二步,因为目标是根据人员信息生成简历表,所以需要一个简历表的模板。[2]蜗牛壳上的小潘同志.CSDN——PYTHON将EXCEL数据自动填充到WORD指定位置中参考资料
- 第三步,根据简历模板生成简历,需要将人员信息和模板中需要填写的内容联系起来。此处在已经找到参考示例的情况下,拟采用手动输入变量和列名的列表,然后依次匹配生成。
- 第四步,照例是根据输入的文件名保存文件。
- 由此确认了最初的输入输出框架:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20"""
输入示例:
OUT:请输入简历数据源
IN:test.xlsx
OUT:已导入数据源
OUT:请输入简历模板:
IN:简历模板.doc
OUT:已导入简历模板
OUT:请输入模板变量的信息,按顺序输入,以","分割。
IN:name,ID,Certificate,University,graduate,phone
OUT:请输入数据源中对应模板变量的列名,按顺序输入,以“,”分割
IN: 姓名,身份证号码,资质证书,毕业学校,毕业时间,手机号码
OUT:已生成简历表,请输入存放文件的名字
IN:简历表.doc
OUT:已完成导出
"""编写过程梳理
根据设计好的输入输出示例,我画出了相应的流程图

然后在流程图基础上罗列出基本的代码框架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# ====================加载简历表信息数据源====================
DataSourceInput = input("请输入简历数据源:");
DataSource = ...
# TODO:导入简历表数据源,可以参考实例1
# ====================加载简历表模板 ====================
TemplateInput = input("请输入简历模板:");
Template = ...
# TODO:导入简历表模板
# ====================将模板中的变量与数据源中的人员信息一一匹配 ====================
VarListInput = input("请输入模板变量的信息,按顺序输入,以英文逗号“,”分割")
HeaderlistInput = input("请输入数据源中对应模板变量的列名,与上述模板变量对应,以中文逗号“,”分割")
# TODO: 对输入的字符串进行分割,转为列表list,便于读取操作
# TODO: 安装Varlist中的变量名和Headerlist中的对应列一一赋值匹配并保存。
# ====================批量渲染简历表 ====================
# TODO:根据模板依次渲染
# ====================保存生成的简历表到文件 ====================
SaveFile = input("请输入您想要保存的文件名:")
# TODO:保存文件根据代码框架,罗列TODO,并根据自己对python中列表、字典等数据结构的了解和条件、分支、循环等语句的运用,提取相应的搜索关键词,确定搜索方向。
因为要考虑到使用者的具体感受,所以推荐在解决了
TODO以后,再通过print()函数写一些提示性文字,提示输入示例,引导输入。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66from docxtpl import DocxTemplate
# docx-template是一个使用jinjia2方法渲染docx文件的包。
# 这个包通过对docx模板中 {{ var }} 的处理,实现模块化、自动化的处理word文件。
import pandas as pd
pd.set_option('display.float_format',lambda x : '%d' % x) #禁用科学计数法
from pandas import Series, DataFrame
# pandas包用于对excel文件进行读取和行列操作。
from docx import Document
from docxcompose.composer import Composer
# 使⽤python-docx扩展库和docxcompose扩展库实现简历表合并
# ====================加载简历表信息数据源====================
DataSourceInput = input("请输入简历数据源:\n例如: test.xlsx \n");
print('文件:', DataSourceInput, '加载中......')
DataSource = pd.read_excel(DataSourceInput)
+ print('已导入数据源')
+ print('=' * 80)
+ print('数据源:',DataSourceInput,'预览')
+ print(DataSource)
+ print('=' * 80)
# ====================加载简历表模板 ====================
TemplateInput = input("请输入简历模板:\n例如: 简历表模板.docx\n");
+ print('简历模板:', TemplateInput, '加载中......')
Template = DocxTemplate(TemplateInput)
+ print('已导入简历模板')
+ print('=' * 80)
# ====================将模板中的变量与数据源中的人员信息一一匹配 ====================
- VarListInput = input("请输入模板变量的信息:")
+ VarListInput = input("请输入模板变量的信息,按顺序输入,以英文逗号“,”分割\n例如:name,ID,Certificate,University,graduate,phone\n")
+ print('=' * 80)
- HeaderlistInput = input("请输入数据源中对应模板变量的列名:")
+ HeaderlistInput = input("请输入数据源中对应模板变量的列名,与上述模板变量对应,以中文逗号“,”分割\n例如: 姓名,身份证号码,资质证书,毕业学校,毕业时间,手机号码\n")
+ print('=' * 80)
VarList = VarListInput.split(",") #出于输入习惯,变量为英文,所以用英文逗号分割
Headerlist = HeaderlistInput.split(",") #出于输入习惯,对应列名为英文,所以用英文逗号分割
+ print("变量参数录入完成,正在根据参数键值对生成简历信息")
contexts = [] #存放生成的所有简历信息和对应值字典的列表容器
for row in range(DataSource.shape[0]): #一重循环,读取数据源的每行信息
context = {} #生成的单人简历信息和对应值
for i in range(len(VarList)): #二重循环,将数据源中的人员信息赋值给存放单人简历信息的context字典
context[VarList[i]] = DataSource.loc[row,Headerlist[i]]
+ print(context)
contexts.append(context) #将赋值完毕的单人简历信息放入存放所以简历信息的列表
# ====================批量渲染简历表 ====================
+ print('=' * 80)
# 根据模板依次渲染
+ print("正在根据简历信息及模板渲染简历表......")
# 新建一个doc文件,用于存放生成的简历表
new_document = Document() #空doc文件
composer = Composer(new_document) #预备用于存放生成的简历表的doc容器,使用Composer函数实例化。
for context in contexts: #依次读取contexts中的每个context单人简历数据字典
Template.render(context) #根据键值对渲染简历表
composer.append(Template) #将渲染好的简历表合并到composer
# ====================保存生成的简历表到文件 ====================
- SaveFile = input("请输入您想要保存的文件名:")
+ SaveFile = input("生成完毕,请输入您想要保存的文件名:\n例如:test.docx\n")
composer.save(SaveFile) #保存合并好的简历表
+ print('文件:', SaveFile , '已保存')变量名 数据类型 变量释义 DataSourceInput 字符串string 输入的简历表数据源文件名 DataSource 二维数据表结构DataFrame 根据文件名获取简历表数据源后存放于此变量 TemplateInput 字符串string 输入的简历表模板文件名 Template 模板文件 docxtpl包特有的模板数据结构,仅用于渲染 VarListInput 字符串String 模板文件中的变量的信息 HeaderlistInput 字符串String 简历表数据源中与模板文件内变量对应的表头 VarList 列表list 将VarListInput按英文逗号“,”分割后获得的列表,便于操作 HeaderList 列表list 将HeaderListInput按中文逗号“,”分割后获得的列表,便于操作 context 字典dict 个人简历表的键值对信息,形如 {'name':姓名,'age':年龄,'education':学历}contexts 列表list 存放配对完毕的个人简历表字典的容器 SaveFile 字符串String 存放切片结果的文件的名字 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62from docxtpl import DocxTemplate
# docx-template是一个使用jinjia2方法渲染docx文件的包。
# 这个包通过对docx模板中 {{ var }} 的处理,实现模块化、自动化的处理word文件。
import pandas as pd
pd.set_option('display.float_format',lambda x : '%d' % x) #禁用科学计数法
from pandas import Series, DataFrame
# pandas包用于对excel文件进行读取和行列操作。
from docx import Document
from docxcompose.composer import Composer
# 使⽤python-docx扩展库和docxcompose扩展库实现简历表合并
# ====================加载简历表信息数据源====================
DataSourceInput = input("请输入简历数据源:\n例如: test.xlsx \n");
print('文件:', DataSourceInput, '加载中......')
DataSource = pd.read_excel(DataSourceInput)
print('已导入数据源')
print('=' * 80)
print('数据源:',DataSourceInput,'预览')
print(DataSource)
print('=' * 80)
# ====================加载简历表模板 ====================
TemplateInput = input("请输入简历模板:\n例如: 简历表模板.docx\n");
print('简历模板:', TemplateInput, '加载中......')
Template = DocxTemplate(TemplateInput)
print('已导入简历模板')
print('=' * 80)
# ====================将模板中的变量与数据源中的人员信息一一匹配 ====================
VarListInput = input("请输入模板变量的信息,按顺序输入,以英文逗号“,”分割\n例如:name,ID,Certificate,University,graduate,phone\n")
print('=' * 80)
HeaderlistInput = input("请输入数据源中对应模板变量的列名,与上述模板变量对应,以中文逗号“,”分割\n例如: 姓名,身份证号码,资质证书,毕业学校,毕业时间,手机号码\n")
print('=' * 80)
VarList = VarListInput.split(",") #出于输入习惯,变量为英文,所以用英文逗号分割
Headerlist = HeaderlistInput.split(",") #出于输入习惯,对应列名为英文,所以用英文逗号分割
print("变量参数录入完成,正在根据参数键值对生成简历信息")
contexts = [] #存放生成的所有简历信息和对应值字典的列表容器
for row in range(DataSource.shape[0]): #一重循环,读取数据源的每行信息
context = {} #生成的单人简历信息和对应值
for i in range(len(VarList)): #二重循环,将数据源中的人员信息赋值给存放单人简历信息的context字典
context[VarList[i]] = DataSource.loc[row,Headerlist[i]]
print(context)
contexts.append(context) #将赋值完毕的单人简历信息放入存放所以简历信息的列表
# ====================批量渲染简历表 ====================
print('=' * 80)
# 根据模板依次渲染
print("正在根据简历信息及模板渲染简历表......")
# 新建一个doc文件,用于存放生成的简历表
new_document = Document() #空doc文件
composer = Composer(new_document) #预备用于存放生成的简历表的doc容器,使用Composer函数实例化。
for context in contexts: #依次读取contexts中的每个context单人简历数据字典
Template.render(context) #根据键值对渲染简历表
composer.append(Template) #将渲染好的简历表合并到composer
# ====================保存生成的简历表到文件 ====================
SaveFile = input("生成完毕,请输入您想要保存的文件名:\n例如:test.docx\n")
composer.save(SaveFile) #保存合并好的简历表
print('文件:', SaveFile , '已保存')
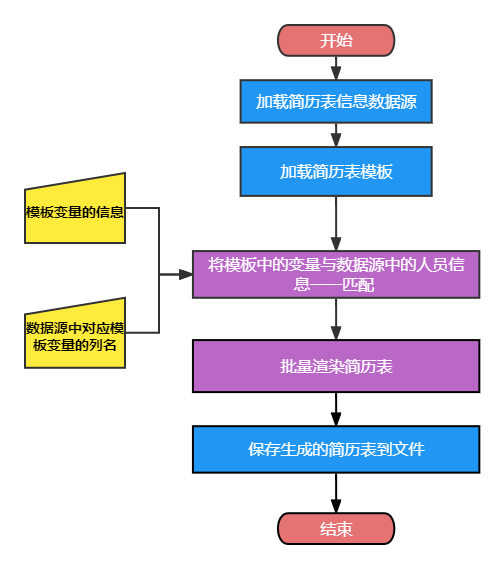
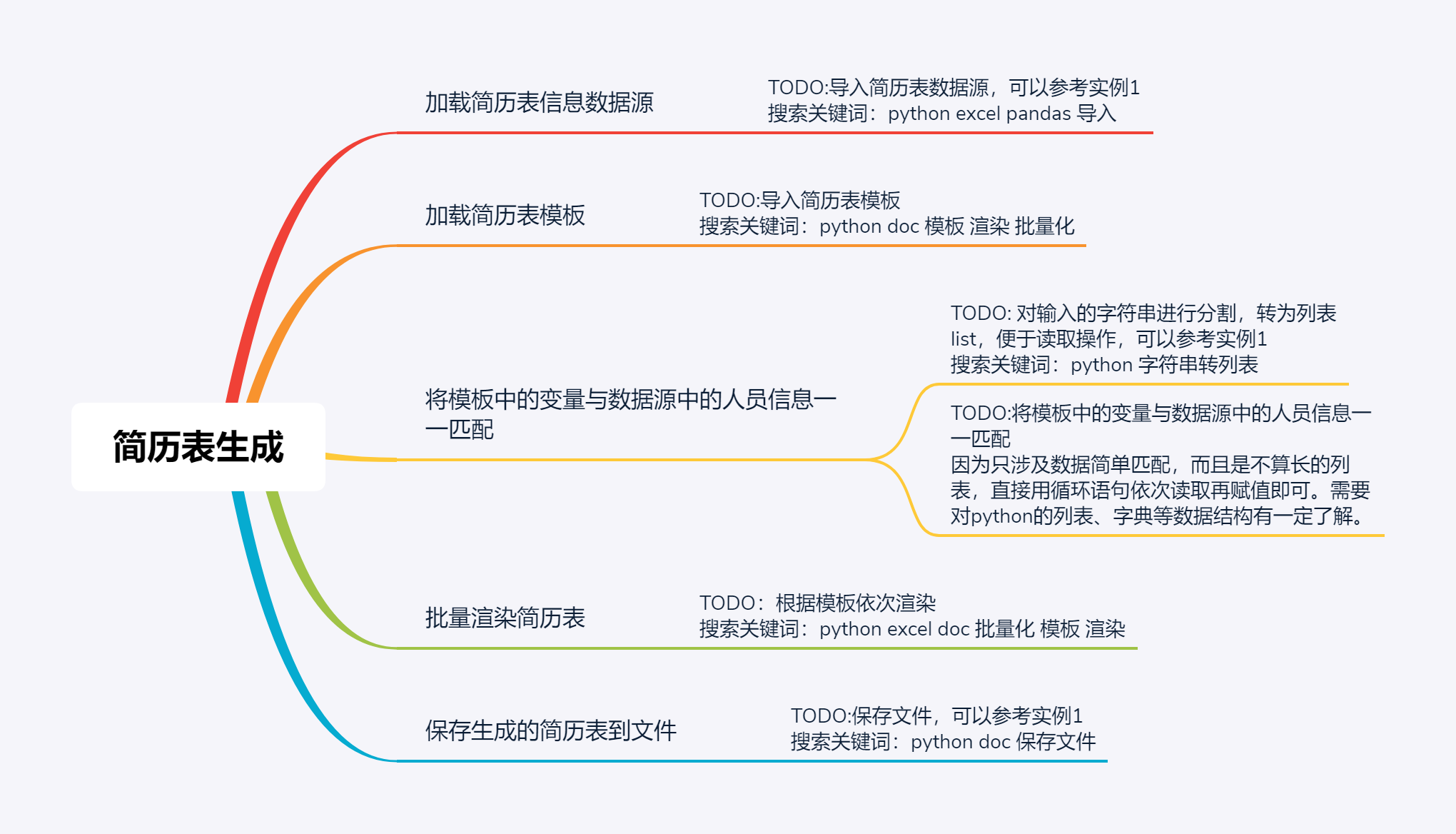
搜索思路
罗列出代码框架后,根据已经提出的需要解决的问题,也就是注释中的TODO,这个就需要在了解python基本的数据结构和条件、循环及其他语句的前提下,列出搜索的方向。
搜索的方向需要活用提炼出的技术栈技术栈,IT术语,某项工作或某个职位需要掌握的一系列技能组合的统称。,通过必要的技术栈来查找需要的第三方库,别人写好的示例代码,可行的数据操作方向。
以实例一中的“TODO:获取列名为职业资格名称1的列的所有值,保留职业资格名称1为测绘作业证的前几项”这个问题为例,首先搜索
python excel 数据处理,搜索到的结果推荐我使用openpyxl[3]使用Python自动化Microsoft Excel和Word参考资料、xlrd[4]solocoder.简书——Python数据处理(二):处理 Excel 数据[OL],2019-02-16参考资料、xlwings[5]zcdmw.知乎专栏——xlwings最全操作;10秒搞定Xlwings全套操作[OL],2020-09-12参考资料、pandas[6]HelenLee.博客园——【python】读取excel的行列内容,pandas,超详细!!![OL],2020-03-02参考资料这些第三方包库。根据形似关键词
python "excel" "openpyxl" 数据处理搜到的参考资料和给出的参考示例,最终我是确认用pandas比较方便。(此处用到了一些基础的搜索引擎语法,用引号包裹[7]黑客老鸟-五竹.知乎——搜索引擎实用语法[OL],2021-02-06参考资料要确保存在于搜索结果中的必要技术栈)然后进一步界定技术栈,继续搜索,
pandas excel 数据处理。搜索过程中要多优化搜索方向,确定指定的技术内容,之后可以搜索
pandas excel 指定位置数据、pandas excel 行列操作、pandas DataFrame 去重 合并等。- 当确定了使用的包库,并且找到了相应的案例以后,下一步就是进一步了解案例中用到的函数方法。比如我在两个实例里用到的isin()方法主要用于确认数据集中的数值是否被包含在给定的列表中。、append()方法主要用于在现有数据上追加新的数据对象,例如数据合并操作。,了解这些函数方法的具体参数,用这些已经封装好的函数方法去完成我们期望的一些复杂操作。
注意事项:
- 在查找解决方案时尽量避免抱着一蹴而就的心态,想着直接找到别人做好的轮子,虽然偶尔确实会有,比如在找简历表生成示例时,根据关键词
python excel word 自动化,搜到了PYTHON将EXCEL数据自动填充到WORD指定位置中 - 不能依赖于运气,查找方向应该以别人整理好的归纳性的示例为主,比如根据关键词
pandas excel 行列读取搜到了【python】读取excel的行列内容,pandas,超详细!!!,这篇里就提供了各种读取指定行,指定列,多行多列,特定行列的方法。 如果根据关键词实在查不到现成的示例,那就只能学习一下所需第三方包库的具体用法了,比如根据关键词
pandas 中文文档搜索十分钟入门 Pandas搜索时要注意看参考文章的发布时间,因为python的第三方包库是日新月异的,可能以前比较好用的包库,现在已经有了更好用的替代品。也可能旧版的包库不兼容于最新版的python,这会间接导致遇到一些兼容性报错。结合文章发布时间选择更新的技术是大势所趋。
- 查阅的参考教程以知乎、掘金、博客园等为优先,这些网站的原创程度高,排版也较好。尽量避免参考CSDN、简书、腾讯云社区等,这些网站的文章部分是通过爬虫爬取或者第三方推送的方式发布的,抛开盗版这个话题不谈,爬虫获取的文章极大概率存在排版错乱问题,而python语法中,缩进是有具体含义的,排版混乱会直接导致python代码无法正常运行。
扩展内容
此项主要是简单讲解一下如何将编写好的python程序(.py后缀)打包为可执行文件(.exe后缀)。
其实就两行代码。
- 安装pyinstaller,在任意位置打开终端,输入指令安装[8]鱼丸丶粗面 .脚本之家——Python打包为exe详细教程[OL],2021-05-18参考资料:
1
pip install pyinstaller
- 在写好的python程序同级目录打开终端,运行指令,其中
test.py为待打包的python程序。1
pyinstaller.exe -F .\test.py
- 在实例二的打包过程中,遇到了缺少docxcompose/templates/custom.xml的报错。需要通过—add-path参数将缺少的文件导进去[9]lsyoulin .灰信网——用PYTHON实现WORD多文档合并[OL],2020-07-07参考资料。查找到我的custom.xml文件在
D:\ProgramData\Anaconda3\Lib\site-packages\docxcompose\templates\custom.xml,1
pyinstaller -F --add-data D:\ProgramData\Anaconda3\Lib\site-packages\docxcompose\templates\*.*;docxcompose\templates\. .\test.py

